
MagVin Lab v3.2: The Orchestration Detour
Version 3.2 started with a security audit and a detour through Docker Swarm that lasted exactly one day. What remained was the real work: API versioning, service layer extraction, and three abstractions that turn sovereignty from philosophy into architecture. The foundation held well enough to make the next step visible—Kubernetes in v4.0.
MAGVIN LAB
Lance
1/16/20265 min read
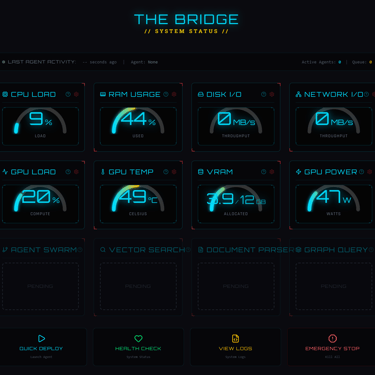
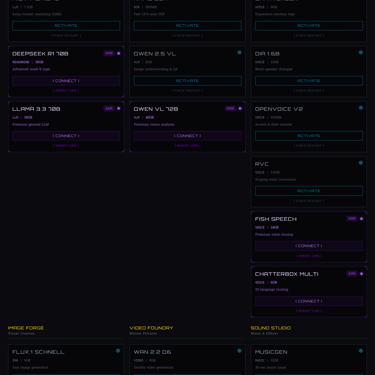
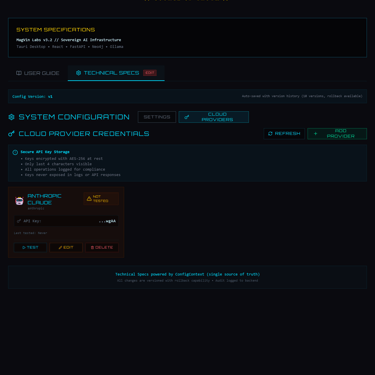
Screenshots from MagVin Lab v3.2
Context
Version 3.1 ended with momentum. The Neural Grid was organized, Documentation Governance v2.0 meant the system could finally document itself, and the Unified Cortex architecture was in place. The session logs showed steady progress, and they also showed that the codebase had grown large enough to warrant a comprehensive review.
So v3.2 began with Priority 0: a full-stack security audit before continuing development.
The Audit
The audit surfaced 39 findings across four severity tiers.
· Environment variables need encryption at rest
· Docker control endpoints needed authentication
· The Content Security Policy needs to be tightened
· Rate limiting needed implementation.
Claude Code conducted the security assessment and assigned a B- grade (72/100), thus providing a baseline. Addressing the findings took priority, with critical issues first, then high, then medium, then low. By the time Priority 0.9 was completed, Claude’s self-assigned grade had improved to A- (90/100), with 36 of 39 items resolved. The remaining three required architectural decisions that would come later in v3.2.
The audit accomplished exactly what audits should: it provided visibility into where the foundation could be strengthened.
The Orchestration Detour
One of the priority findings involved secrets management, and the solution seemed straightforward: migrate to Docker Swarm and use its encrypted secrets.
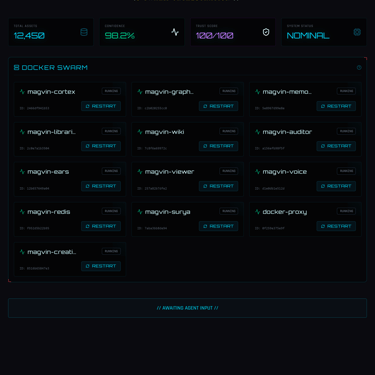
The migration worked, with thirteen services deployed to Swarm, secrets encrypted, and the security posture improved. Then I tried to schedule GPU workloads and discovered that Docker Swarm cannot schedule GPUs on Windows Desktop. Ollama had to stay on the host, which meant the orchestration layer was managing twelve containers while the most compute-intensive service ran outside it. This was a temporary runtime exception forced by GPU scheduling constraints; once we rolled back to Compose, Ollama returned to container control and the doctrine held.
At the time, I thought Swarm represented a modern infrastructure for supporting agentic AI workloads, hence the name. However, research revealed that it was an older orchestration system, and the GPU scheduling limitation confirmed that it was not the right fit for this project. The detour lasted only a day before the decision became clear.
ADR-008 documented the rollback to Docker Compose with dotenvx encryption, which provided comparable guarantees for my single-node development environment. The Swarm-era documents moved to an archive folder, and the lesson stayed: simplicity serves the goal.
Architecture Maturation
With the orchestration question resolved, the architecture work could proceed.
The first discovery came from API versioning. Moving all 34 endpoints behind /api/v1/ prefixes, following the pattern used by Stripe, GitHub, and other production APIs that are expected to evolve, required updating every frontend fetch call. That process revealed 36 hardcoded localhost:8000 URLs scattered across twelve components, which led directly to the next improvement.
The frontend API client consolidated those calls into a single module, moved the base URL configuration to the Settings panel, and added interceptors for consistent error handling. The components became simpler while the system became more configurable.
The backend received similar treatment through a service layer extraction that reduced main.py from 501 lines to 368, pulling business logic into dedicated classes that could be tested independently. Rate limiting, input validation, and proper exception handling addressed gaps the audit had identified.
Dependency management modernized as well after an evaluation that covered pip-tools, Poetry, PDM, and Pixi before landing on uv, the Rust-based package manager from Astral. The tooling is ten to one hundred times faster than pip with first-class Docker support, built by the same team behind Ruff. ADR-006 documented the decision, and the build times validated it.
The functional goals from v3.1, specifically wiring the Neural Link and persisting Cortex conversations, were sidelined as the infrastructure constraints took precedence. Those remain on the roadmap for v4.0.
API versioning and dependency management lack the drama of a new feature, but they are the work that lets the interesting work happen. A system with versioned APIs can evolve, and a system with consolidated fetch calls can be reconfigured. The foundational work matters.
The Abstractions
Three architectural decisions in v3.2 exist as interfaces for what comes next.
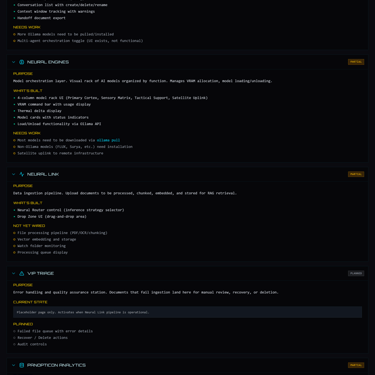
The API Key Vault stores credentials in an encrypted SQLite database using sqlcipher with AES-256. Keys are masked in the UI, audited on every access, and never logged. The implementation provides what environment variables cannot: audit trails, a management interface, and the foundation for per-provider spending limits. While PostgreSQL handles application data, I chose a local encrypted SQLite file for secrets to ensure the key vault remains portable and decoupled from the container stack, adhering to the isolation principle established in Desk v4.
The LLM Provider Abstraction defines a common interface that any provider (Ollama, OpenAI, Anthropic, Groq) implements. The internal format follows OpenAI's conventions because that has become the industry standard. When a new provider appears, it adapts to MagVin Lab's interface rather than requiring MagVin Lab to adapt to it.
Agent Spending Controls enforce budget caps, approval modes, and cost estimation before any cloud API call. My research surfaced a consistent finding across industry sources: organizations are deploying AI agents faster than they can govern them. Building the controls before the agents exist means the safeguards are architectural rather than afterthoughts.
These abstractions embody what Goswami (2025) calls the three pillars of sovereignty, a framework that validates and extends the 'local-first' philosophy I established earlier in this series:
· Architectural Control: Running the stack locally with explicit knowledge of every dependency.
· Operational Independence: Enforcing your own policies rather than accepting vendor terms.
· Escape Velocity: The ability to leave any provider without rewriting your codebase.
Sovereignty does not mean isolation from the cloud. It means controlling how and when cloud resources are used, with full visibility into costs, explicit approval gates, and the ability to change providers at will. The abstractions built in v3.2 make that control possible.
The Kubernetes Decision
By mid-January, the system was stable after the Swarm rollback, security grade at A-, and architecture patterns aligned with industry standards. Development could have continued on this foundation.
Instead, I kept returning to the same question: if MagVin Lab is meant to demonstrate platform engineering, why is it running on Docker Compose?
Compose works and handles the current requirements well. But Compose cannot express what a NeuralEngine should be as a first-class resource, cannot define custom controllers that manage VRAM budgets or thermal protection, and cannot provide the declarative infrastructure that Kubernetes enables.
The decision documented in ADR-014 was about recognizing that cloud-native is about how you architect, not where you deploy. Running Kubernetes locally costs nothing while teaching patterns that transfer directly to production infrastructure. The educational value is significant: Kubernetes is the industry standard, and learning it properly positions the project for real-world deployment scenarios (even if that is not the goal). The technical complexity is less of a concern, given that Claude Code and Gemini are available to assist with implementation details.
The migration warranted a major version bump because Docker Compose to Kubernetes changes every deployment command, every operational procedure, and every mental model for how the system runs. Users following v3.x documentation cannot apply it to v4.0, which is the definition of a breaking change.
Version 3.2 ended because it succeeded well enough to make the next step visible.
The Lesson
Earlier in this series, I wrote that every earlier iteration contributed to the doctrine governing the current version. That remains true. What v3.2 added was the recognition that foundations benefit from periodic re-verification.
The audit provided visibility. The detour through orchestration clarified the complexity that the project actually needed. The architecture work created the interfaces that enable the features.
Version 3.2 was about re-establishing the foundation, and every abstraction exists to enable what comes next.
What Comes Next
In v3.1 I projected v3.3-v3.6, but the Kubernetes decision made that path artificially incremental. I'm folding that work into the v4.0 rebuild. Version 4.0 begins with an empty repository and a complete documentation structure. The migration plan sequences TypeScript before component migration, SQLAlchemy before service copy, and basic Kubernetes before Helm charts before custom operators.
The first custom resource definition will be NeuralEngine (the Kubernetes kind name): a declaration of what models should be loaded, their VRAM budgets, and their priority order. Kubernetes manages the resource, while a custom controller enforces the constraints, allowing the system to describe its desired state and letting the platform make it so.
That is the vision. The foundation to support it continues to evolve.
Reference
Goswami, S. (2025, November 12). Defining sovereign AI for the enterprise era. SiliconANGLE. https://siliconangle.com/2025/11/12/defining-sovereign-ai-enterprise-era-thecube/
Phone +1-509-931-1685
© 2026. All rights reserved.
Email info@magvinlabs.com
Address 522 West Riverside Avenue
Spokane, WA 99201
Find MagVin on LinkedIn