
MagVin Lab v3.1: The Unified Neural Architecture
Version 3.1 transformed scaffolding into substance. Over twenty local models now sit organized across six functional categories in the Neural Engines tab, each displayed with VRAM footprint and thermal awareness. The Unified Cortex brings conversational AI inside the Lab itself, and Documentation Governance v2.0 formalizes what earlier versions let drift. The system has grown substantial enough that future versions narrow deliberately.
MAGVIN LAB
Lance
1/8/20265 min read


Screenshots from MagVin Lab v3.1
Context
The holidays slowed our pace but not the thinking. Three weeks between versions gave me space to reflect on what v3.0 had established and what v3.1 needed to accomplish.
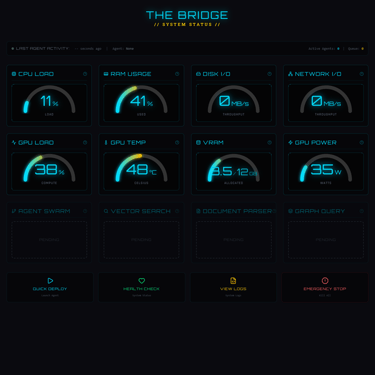
Version 3.0 proved the architecture could work: FastAPI serving typed endpoints, React rendering exactly what I specified, and containerized services maintaining the sovereignty mandate throughout. But the interface was scaffolding. Tabs existed and navigation functioned, yet most of what those tabs promised remained unwired. The Bridge displayed telemetry while Neural Engines showed a vision of organized models, but everything else awaited its turn.
The purpose of v3.1 was to transform that scaffolding into substance.
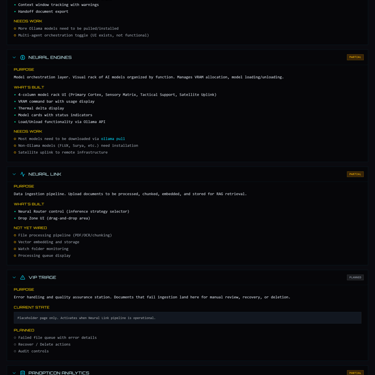
The Neural Grid
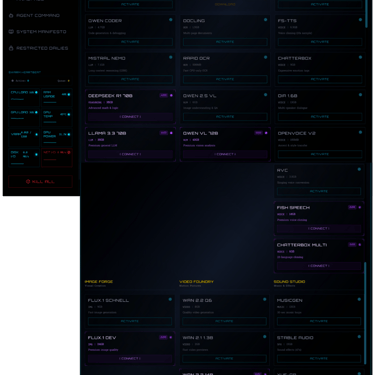
I expanded the Neural Engines tab from concept to comprehensive matrix, and what had been a demonstration of intent became an organized fleet ready for activation. Six columns now categorize the fleet's capabilities by function (managed via Ollama and specialized containers):
Primary Cortex holds the language and reasoning models: Llama 3.1 8B for general work, Deepseek R1 8B for chain-of-thought reasoning, Qwen Coder for code generation, and Mistral Nemo for long-context tasks requiring its 128K window.
Optical Scanner handles document analysis through Florence-2 for receipt and form scanning, Docling for multi-page documents, Rapid OCR for fast CPU-only extraction, and Qwen 2.5 VL for image understanding.
Vocal Matrix manages speech and sound with Kokoro TTS, Whisper V3 for transcription, F5-TTS for voice cloning, Chatterbox for expressive emotion tags, and several others including OpenVoice V2 for accent transfer and RVC for singing voice conversion.
Image Forge contains Flux.1 Schnell for fast generation and Flux.1 Dev for premium quality output.
Video Foundry holds the Wan family of video models alongside Hunyuan Video for cinematic output.
Sound Studio manages Musicgen, Stable Audio, and Yue-GP for music generation and sound effects.
The audio-visual columns exist because the Lab was always meant to support more than document processing. My wife is a social media influencer, and supporting her content production workflow is part of what this system needs to do. Building those capabilities into the architecture from the start means the infrastructure will be ready when the time comes to use it.
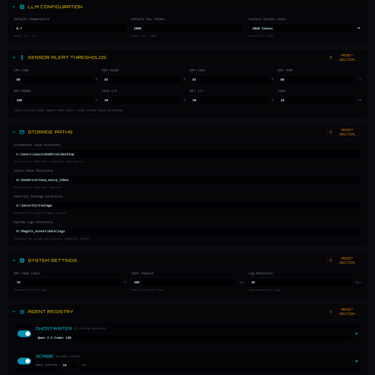
The interface displays each model with its VRAM footprint, letting me calculate loading sequences before committing GPU memory. The VRAM Command bar at the top shows current allocation against the 12GB ceiling of the RTX 4070 Super, while Thermal Delta displays the current GPU temperature against the configured limit. Cards appear in cyan for local models ready for activation, while the purple cards tagged A100 or H100 indicate models planned for rented cloud compute through RunPod when local VRAM proves insufficient. The distinction matters because it preserves the sovereignty principle: cloud resources remain optional and explicit rather than hidden dependencies.
The models are catalogued and wored for inference through Ollama, but honest assessment requires noting that real testing awaits a functional Unified Cortex. The interface shows what is possible, and validation will begin in v3.2 as the Cortex work progresses. I chose to organize comprehensively before testing incrementally because building the full picture first means knowing exactly what I am working with.
The Unified Cortex
The Lab now has its own conversational interface, and this changes how I can use the system.
The Unified Cortex connects to Ollama, but it exists so that I never have to leave the Lab to interact with the models. With this infrastructure running, it would be a waste to minimize the window and work through Ollama's terminal or web interface directly. The Cortex keeps everything in one environment: model selection, conversation history, context tracking, and inference statistics all visible without switching tools.
The interface provides a model selector dropdown that lists every available model from Ollama, alongside a conversation sidebar displaying existing threads with options to create, rename, or delete. Context window tracking shows token usage in real time, which matters when working near the limits of smaller models. Inference statistics display tokens per second, latency, and total tokens consumed, giving immediate feedback on how the hardware is performing under load.
The design is privacy-first because conversations stay local and nothing routes through external servers unless I explicitly choose a satellite model that requires it. This is the sovereignty mandate in practice: the data lives where I control it.
The honest scope is that the interface functions and conversations work, but Neo4j integration for persistence is not yet wired. Conversations do not yet survive application restarts, which means the system is functional for testing and iteration but not yet ready for production use where I would expect history to persist. Wiring that persistence is a primary goal for v3.2.
Documentation Governance v2.0
The development workflow shifted tools during this version, and the documentation system evolved alongside it.
Version 3.0 was built with Google Gemini through Antigravity, but when I began work on v3.1 in earnest, I wanted a second opinion. Claude Code provided a full-stack audit, examining what Antigravity had built with fresh eyes. There was nothing wrong with the earlier work, and audits always surface findings; that is precisely their purpose. But working with Claude Code through VS Code felt right, and I found no reason to switch back. The pairing became the new workflow, and it stuck.
The complexity of the system was also reaching a threshold where the documentation itself was beginning to drift. Six model categories, a chat interface, and eight tabs at varying stages of completion meant that keeping track of what worked, what remained stubbed, and what decisions led to the current state required more than occasional notes. The solution was to make documentation part of the infrastructure itself.
Documentation Governance v2.0 formalizes what earlier versions learned through failure. Auto-update rules are now baked into Claude's instructions: CURRENT_STATE.md gets updated at the end of every session, session logs capture work as it happens, and architectural decision records document significant choices. Context anchors preserve hardware specifications, known constraints, and user preferences so that each session begins with accurate information rather than stale assumptions.
The governing rule is simple: the user should never need to ask for documentation updates. If something changed, the documentation should already reflect it. This is the discipline I articulated at the end of MagVin Desk V2, where the mantras first took shape, now applied to our documentation itself.
Quality > speed.
Accuracy > speed.
Fidelity = paramount.
If the system is worth building, the documentation is worth automating.
The deeper judgment here is recognizing that human-AI collaboration is itself a system requiring design. Context does not persist automatically between sessions, and the operator becomes the only source of continuity unless the documentation infrastructure compensates. Building that infrastructure treats the collaboration as seriously as the software it produces.
What Comes Next
Version 3.1 ended because the system had grown substantial enough to warrant a deliberate pause. A model fleet organized across six categories, a chat interface wired to local inference, documentation that updates without prompting, and an audit completed by a fresh set of eyes. That is enough infrastructure that continuing without verification would ignore everything that previous versions have taught.
The discipline exercised here is not fear of failure but instead respect for the complexity of the system.
Version 3.2 carries three specific goals:
Adjust the existing stack in line with new audit findings
Finish the Unified Cortex with conversation persistence and full model integration
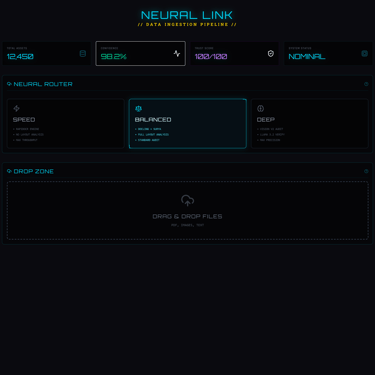
Wire up Neural Link with its file processing pipeline
These goals are sequential and connected: the Cortex must work before the models can be properly tested, and Neural Link depends on stable foundations underneath it.
The roadmap beyond v3.2 narrows deliberately:
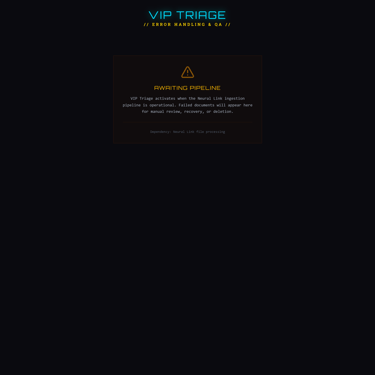
v3.3: Audit by committee (Claude Code, Gemini through Antigravity, and GPT) followed by VIP Triage implementation
v3.4: Agent Command combined with Restricted Dailies
v3.5: Panopticon Analytics
v3.6: Audit by committee, marking a stability and robustness milestone
The scope narrows because the codebase has grown wide enough that each version requires careful work and proper audits at every step. Later versions focus on single capabilities rather than broad expansion because that is what I demand, as captured in my mantras.
The system must become both robust and complete, one verified layer at a time, and v3.1 was a positive step in that direction.
Phone +1-509-931-1685
© 2026. All rights reserved.
Email info@magvinlabs.com
Address 522 West Riverside Avenue
Spokane, WA 99201
Find MagVin on LinkedIn