
MagVin Desk v3: The Simplicity Pivot
I cut 68% of the codebase and dropped from four OCR engines to three. The benchmark that had justified all that earlier complexity? The simpler system handled it at 97% success. Less code, better results.
MAGVIN DESK
Lance
10/2/20253 min read
Context
Version 2 had taught me something I should have known already: more code does not mean more capability. The 38% growth, the four-engine stack, the Smart Content Router that was choked by complexity; all of it pointed to the same conclusion. I had been building complexity instead of solving problems, and the codebase had grown into something I could no longer maintain with confidence.
So I started over, not with optimisation or refactoring, but with deletion. Version 3 began with a question that felt almost reckless after months of expansion: what if I cut everything that wasn't essential to OCR?
What I Built
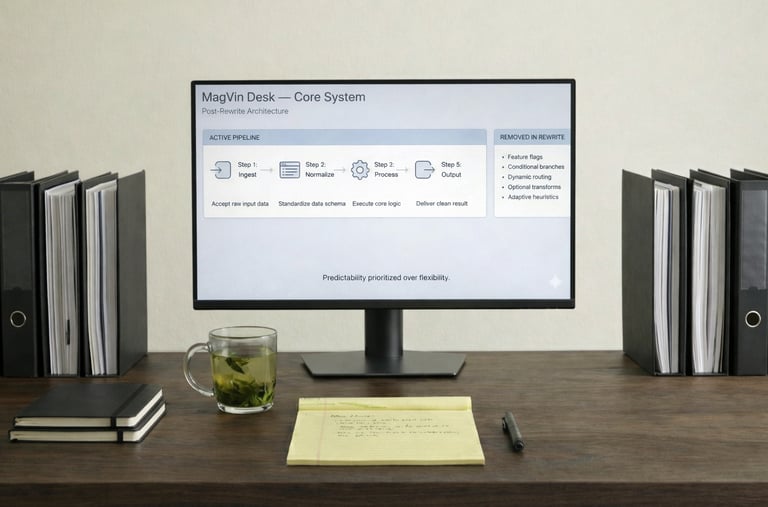
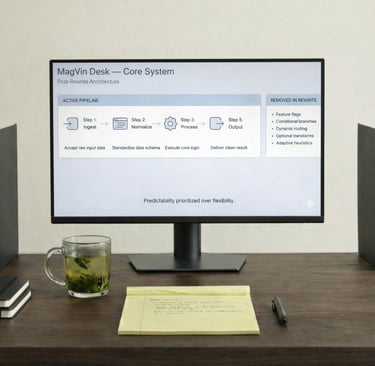
The reduction was severe. 14,193 lines became 4,428, a 68% cut that felt more like surgery than development. Twenty-seven classes collapsed to eleven, each with a single responsibility that I could explain in one sentence. The four-engine OCR stack dropped to three: Tesseract for speed, EasyOCR for multilingual capability, and TrOCR for handwriting and complex layouts.
PaddleOCR disappeared entirely, and with it went the Windows DLL errors that had plagued every Version 2 session. I attempted to integrate Surya OCR as well, but environment conflicts made it unstable, so I let it go rather than force compatibility. That decision would matter later.
The eleven classes that remained followed a strict architecture:
OCREngine (abstract base): Defined the interface that all engines implemented
TesseractEngine, EasyOCREngine, TrOCREngine: Individual engine wrappers with consistent methods
AdvancedOCRProcessor: Pipeline orchestration without feature bloat
ImagePreprocessor: Adaptive enhancement based on document quality analysis
AdvancedAnalytics: Performance tracking that feeds future optimisation
SystemCapabilities, LanguageDetector, ModelRouter, SystemMonitor: Focused utilities that did one thing well
Output standardisation followed the same principle. Markdown only, with YAML front matter that captured metadata consistently: timestamps, source paths, confidence scores and processing notes. The database stayed clean because the inputs were predictable, and the analysis became reliable because the structure never varied.
The GUI
Version 3 introduced the first real application interface, not a CLI wrapper but an actual control surface where I could monitor and manage processing without watching terminal output scroll past. The launcher displayed real-time system health (CPU, memory, GPU utilisation, optimal worker count) while a console showed processing feedback as files moved through the pipeline.
The checkpoint system made long batch runs survivable. Every 50 files, progress is saved to SQLite and JSON, so crashes no longer require a forced restart from zero. The system remembered where it stopped and resumed from there, a capability that transformed overnight processing from gamble to routine.
Self-healing error recovery handled failures without my intervention. When an initial OCR pass failed, the system retried with different preprocessing filters, and when one engine produced low-confidence scores, another engine automatically received the file. Processing continued even when individual files failed, so I could launch a batch and trust it would finish.
What Worked
The 43-file benchmark answered the question I had been afraid to ask: could a simpler system actually perform better than the complex one I had spent months building?
It could. The benchmark included handwritten notes, poor-quality scans, and documents mixing English, Khmer and Thai, exactly the files that had justified all that Version 2 complexity. Version 3 achieved 97.7% success with an average confidence of 92.3%. The complex documents handled fine with focused tools and clear pipelines.
What Broke
Nothing failed catastrophically, and that was the surprise.
After months of fighting brittle systems and cascading errors, Version 3 simply worked. Surya remained problematic, but the three-engine stack handled everything I needed. The reduced codebase meant fewer places for bugs to hide, and the modular architecture meant problems stayed contained when they did occur. The lesson arrived quietly: the system I had spent months overbuilding could have been this simple from the start.
The Lesson
Less code = better results.
Cutting features had not reduced capability; they revealed it because complexity had obscured what the core system could actually do. Isolation prevented cascades, and when components had clear boundaries, failures remained local rather than propagating through interdependent modules. The version that did less accomplished more, which remains counterintuitive even now.
What Came Next
Version 2's lessons remained fresh, and I had no intention of returning to monolithic integration or feature accumulation. But Version 3's success revealed headroom I had not expected.
The GUI worked, but it was still mostly a display. Version 4 would make it configurable: logging options, debugging controls, path selection, and error-handling preferences. Not expansion for its own sake, but selective enhancement that brought backend capability to the front end, where it could be controlled directly.
The question was no longer "what's broken?" It was "what's next?"
Phone +1-509-931-1685
© 2026. All rights reserved.
Email info@magvinlabs.com
Address 522 West Riverside Avenue
Spokane, WA 99201
Find MagVin on LinkedIn