
MagVin Desk v4: The Surfacing
V3's stability created room to surface hidden capability into a real interface: configurable paths, priority presets, hardware monitoring. Isolation solved the dependency conflicts that had plagued earlier versions, but virtual environments could not travel. The system worked on my machine, and that was exactly the problem.
MAGVIN DESK
Lance
10/13/20255 min read

Context
V3's stability revealed its own constraints. While the system processed documents with 97.7% success and reduced the codebase by 68%, its capability remained locked behind hardcoded defaults. Folder paths were stored in configuration files I never touched, logging output was logged to the terminal history before I could read it, and priority settings required editing YAML directly. The power was there, but it was buried beneath assumptions about how the system should behave.
The purpose of V4 was to surface that capability into the interface itself, transforming what had been hidden into something visible, and what had been assumed into something configurable. V4 was not a response to failure; it was an expansion made possible by success.
What I Built
V3 had proven that the core processing pipeline worked. V4's task was architectural: restructuring the codebase into maintainable modules while exposing backend capability through a production interface. The result was a multi-module architecture organised into a production directory:
core/ for the main orchestrator and document router
isolation/ for environment control and engine management
gui/ for the interface layer
analytics/ for performance tracking and session history
The core module acted as an orchestrator, routing documents to whichever engine was best suited for the content type and coordinating results across five OCR engines:
Surya (intended as the specialist for Southeast Asian scripts and complex layout analysis)
TrOCR (transformer-based recognition for handwriting and degraded text)
EasyOCR (broad language coverage with GPU acceleration)
PaddleOCR (restored after V3's removal, now running in its own isolated environment)
Tesseract (the reliable baseline for clean documents)
Each engine ran inside its own isolated Python virtual environment with frozen dependencies, ensuring that one engine's requirements could not conflict with another's. This isolation strategy addressed the DLL-loading errors that had forced PaddleOCR's removal in V3, and with dedicated environments, the problematic engine was successfully restored.
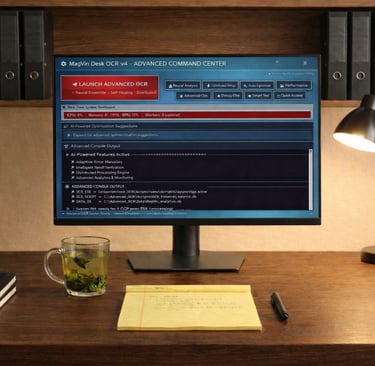
The GUI was built on PySide6 and designed for production use. It featured real-time hardware monitoring with colour-coded status indicators, one-click folder access for inputs, outputs, errors and stubs, and a clean interface that surfaced system operations without requiring terminal access.
The configuration that had previously required editing YAML files now lived in the interface. Users could select input and output directories, toggle logging verbosity and choose between four OCR processing priority modes:
ULTRA (maximum accuracy, 14–16 seconds per file)
QUALITY (high fidelity, 10–12 seconds per file)
BALANCED (6–7 seconds per file)
SPEED (rapid processing, 3–4 seconds per file)
These four presets replaced 143 individual YAML settings, offering meaningful choices that non-technical users could understand without requiring knowledge of underlying engine configurations.
The Hardware Safety System enabled continuous 24/7 operation via auto-throttle at 75–85% resource utilisation, a critical pause at higher thresholds, and GPU temperature monitoring. A SQLite processing database (processing_history.db) tracked session management, per-file engine performance, and processing timestamps, creating an audit trail for every processed document.
Three-tier output routing separated successful conversions, error files and stub placeholders into distinct directories with automatic date-based organisation, ensuring that processed documents never mixed with failures or incomplete extractions.
Statistical fusion allowed engines to run in parallel, with results compared and the highest-confidence output selected for each document. Dynamic weighting based on historical performance was tracked in the database, but I kept it stubbed for future implementation, since the infrastructure was in place while the adaptive logic was awaiting activation.
The codebase grew to approximately 8,000 lines across the module structure.
The system remained personal, but I designed its interface assuming that good architecture should not depend on a single machine’s configuration.
What Worked
PaddleOCR's return validated the isolation strategy in practice. The engine that had caused persistent DLL conflicts in V2 and forced its own removal in V3 now operated reliably inside a dedicated environment, processing documents without destabilising the system. Isolation worked.
The GUI transformed the user experience by surfacing what had been buried, and I could finally see what the system was doing without opening log files or parsing terminal output. Folder paths became editable fields, logging output streamed in real time, debug information appeared on demand, and priority modes offered meaningful choices through a clean interface. The four OCR processing presets gave users control over the accuracy-versus-speed tradeoff without requiring them to understand which engines were being invoked or how confidence thresholds affected output quality.
The Hardware Safety System proved that the machine could run batch processing continuously without thermal concern. Auto-throttling kicked in before resources became critical, and the monitoring dashboard provided real-time visibility into GPU utilisation, RAM consumption and CPU load. I ran multi-hour processing sessions on the RTX 4070 Super without intervention, and the system managed itself.
What Broke
Surya OCR consistently crashed during bounding box detection, failing on more than thirty attempts (returning Exit code 3221226505) and never completing a single file. The engine was intended as the specialist for Southeast Asian scripts and complex document layouts, the component that would unlock many languages with superior accuracy. Its failure blocked production deployment entirely.
EPUB extraction failed due to a missing dependency, and AI Fusion (the LLM-based synthesis layer that would have enabled true neural voting rather than statistical comparison) remained stubbed with TO-DO comments marking where the logic should have been.
Hardcoded paths tied the system to specific Windows drive letters and directory structures. The codebase assumed paths like D:\MagVin_OCR_v4_Production and similar absolute references, making the application functional on my hardware but preventing relocation without manual edits. Automated regression testing (zero tests across V1 through V4) remained absent, meaning every code change required manual validation against the test document suite rather than programmatic verification.
The deeper issue was deployment fragility. Virtual environments solved dependency isolation effectively, but each venv represented a custom configuration built on my specific machine, and reproducing those environments elsewhere required matching Python versions, reinstalling frozen dependencies and hoping that platform-specific binaries behaved identically. As I recognised that future scaling would require reproducible environments, the venv approach revealed its limits. The system worked here, but it could not be handed to anyone else.
The Lesson
Isolation works, but it does not scale through virtual environments alone, because production systems need production architecture.
V4 validated the core principle: separating engines into isolated environments prevents dependency conflicts, restores previously unusable components and enables multi-engine fusion without cascade failures. The approach was sound. However, the implementation method was not ready for deployment beyond a single machine.
What V4 proved was substantial:
Multi-engine fusion worked reliably across five OCR engines
Hardware monitoring prevented crashes during extended batch processing
GUI configurability beats hidden defaults for user experience
Priority mode presets simplified decisions without sacrificing control
What it could not prove was portability. Prototypes learn. Production systems ship.
What Came Next
The isolation principle would carry forward, but the implementation method would change. Docker containers offered what virtual environments could not: reproducible configurations, portable images and client-ready deployment packages. V5 would not build incrementally on V4's codebase; it would rebuild from the architecture up, applying every lesson learned across four versions to a foundation designed for production from the first line of code.
The question had shifted again. It was no longer "does isolation work?" but "how do we ship it?"
Phone +1-509-931-1685
© 2026. All rights reserved.
Email info@magvinlabs.com
Address 522 West Riverside Avenue
Spokane, WA 99201
Find MagVin on LinkedIn